Consistency Levels in Azure Cosmos DB Explained

Azure Cosmos DB is a globally distributed database service that provides well-defined levels of consistency for various application types and needs. With the typical distributed databases, you are usually limited to two levels of consistency: eventual and strong. In Azure Cosmos DB, you have five different consistency levels to choose from based on your requirements.
In this article, I'll explain what all the consistency level offers and means in terms of latency, throughput, and performance to better understand what option to choose when designing your database model for an application.
Also, check out the following articles if you are looking to read more about Cosmos DB:
What is Consistency in CosmosDB?
Consistency is based on the idea of how distributed databases have limitations and tradeoffs between consistency, availability, and partition tolerance. The model takes into consideration the factors of consistency, availability, and also includes the time that affects the latency of the replicas.
The replicas are identical copies of source data sitting in a different region for either DR purposes or for geo-based distribution of systems across the globe where the application fetches the data from its nearest source to reduce the latency and response time.
Unlike the ACID model in a relational database concept which defines consistency based on some sort of data validation check, consistency in CosmosDB is totally different. Consistency in CosmosDB is considered as the uniformity of the data while it's being replicated across the globe to different regions. It defines how and when the data is copied and committed into a replica.
In addition to that, spreading the cluster in multiple regions makes sure that if one node in a cluster goes down, the other node can handle the requests without any downtime.
What is Latency in CosmosDB?
Latency is defined as the time it takes for a server to respond to a request. The shorter the distance between user and server, the lesser the time it takes to return the results and vice-versa. This concept is used heavily in CosmosDB when we talk about the replication of data across multiple regions.
What is Throughput in CosmosDB?
CosmosDB works on the throughput value which refers to number of operations that you can perform on the database. The operations are generally called Request Units (RU) which is a currency abstract for system resources like CPU, IOPS, and memory.
High Throughput → High RUs
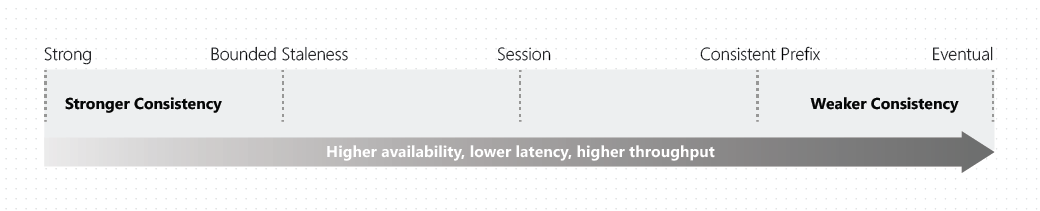
Consistency Models in CosmosDB
As with any feature, there's a steep price you have to pay to be able to leverage that functionality. It is no different with CosmosDB. There is a fundamental tradeoff between the read, availability, latency, and throughput while working with different CosmosDB consistency models.
Let's take a simple example. If you wish to access data across all regions without any order loss, you must consider there will be latency between the data write and availability of the same entry across other regions. The distance between the regions also affects the latency of data replication.
You can change the consistency levels anytime using Azure Portal under your resource settings.
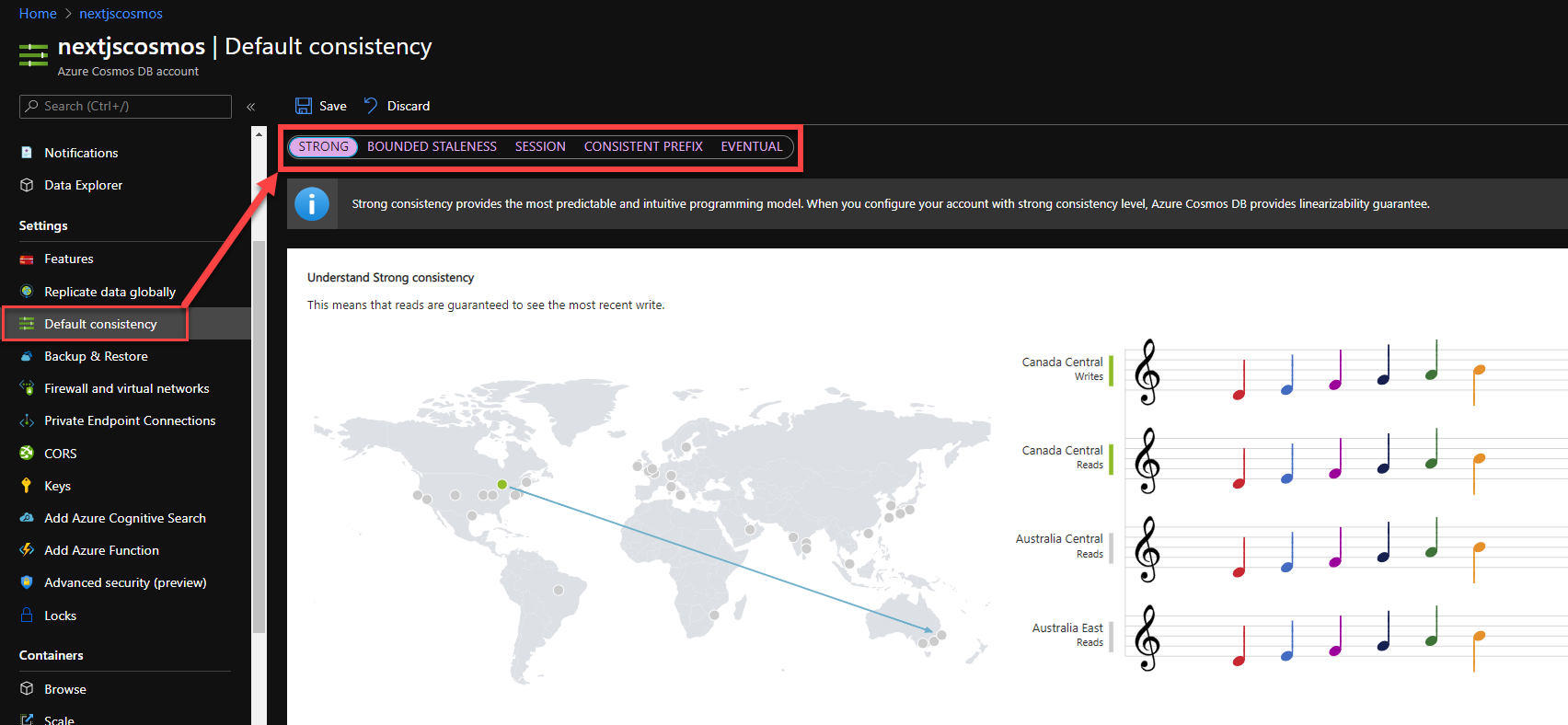 Let's walkthrough the consistency models offered by CosmosDB.
Let's walkthrough the consistency models offered by CosmosDB.
Strong Consistency
Strong consistency is the strictest type of consistency available in CosmosDB. The data is synchronously replicated to all the replicas in real-time. This mode of consistency is useful for applications that cannot tolerate any data loss in case of downtime. Hence, the recovery point objective is Zero.
Strong consistency offers a linearizability guarantee. This means, the order of operation is preserved and the reads are guaranteed to return the most recent version of the item in the database. The client always gets the latest changes in the data when requested.
However, with strong consistency, there is a substantial increase in latency since every write must be replicated and committed to the new regions. As I mentioned earlier, the longer the distance between the replicas, the longer the time it takes to write the changes to the database, hence the increased latency.
In summary, with strong consistency, you get the highest consistency, lower performance, and lowest availability. The latency is also high and this type of model is best suited for Inventory applications, Financial transactions, Scheduling, or Forecasting workloads.
Bounded Staleness
In the Bounded Staleness level, data is replicated asynchronously with a predetermined staleness window defined either by numbers of writes or a period of time. The reads query may lag behind by either a certain number of writes or by a pre-defined time period. However, the reads are guaranteed to honor the sequence of the data. As the staleness window approach, the data replication is triggered on the database account making the database to update the new entries since the last change.
When you choose bounded staleness, you get to choose either (a) the number of versions of the item or (b) the time interval reads might lag behind the writes.
In summary, the data is consistent beyond the user-defined time or operations threshold. The performance of bounded staleness is better than the strong consistency however the availability is still low due to inherent lag for the replication. This level is used for apps that don't need to fetch data in real-time, however still in the order, it was written.
Session
The session consistency is the default consistency that you get while configuring the cosmos DB account. This level of consistency honors the client session. It ensures a strong consistency for an application session with the same session token. What that means is that whatever is written by a session will return the latest version for reads as well, from that same session.
In summary, session consistency provides strong consistency for the session, ensuring the data stays up to date for any active read-write session. The availability of the data is relatively high with lower latency and higher throughput than the bounded staleness. The possible candidate for this kind of model could be a typical e-commerce application, social media app, and other similar services with persistent user connection.
Consistent Prefix
The consistent prefix model is similar to bounded staleness except, the operational or time lag guarantee. The replicas guarantee the consistency and order of the writes however the data is not always current. This model ensures that the user never sees an out-of-order write.
For example, if data is written in the order A, B, and C, the user may either see A, A,B or A,B,C, but never out-of-order entry like A,C or B,A,C. This model provides high availability and very low latency which is best for certain applications that can afford the lag and still function as expected.
Eventual
Eventual consistency is the weakest consistency level of all. The first thing to consider in this model is that there is no guarantee on the order of the data and also no guarantee of how long the data can take to replicate. As the name suggests, the reads are consistent, but eventually.
This model offers high availability and low latency along with the highest throughput of all. This model suits the application that does not require any ordering guarantee. The best usage of this type of model would be the count of retweets, likes, non-threaded comments where the count is more important than any other information.
Table Summary
| Levels | Consistency | Availability | Latency | Throughput |
|---|---|---|---|---|
| Strong | Highest | Low | High | Low |
| Bounded Staleness | High | Low | High | Low |
| Session | Moderate | High | Moderate | Moderate |
| Consistent Prefix | Low | High | Low | Moderate |
| Eventual | Low | High | Low | High |
Conclusion
I hope that helps you clear some of the doubts around the different consistency models available in CosmosDB. Ideally, for decisions on what to choose, the consistency level for CosmosDB should be one level stronger than your actual needs. But this does vary depending on your application workflow and needs.
Drop a comment if you think I missed something. Reach out to me on Twitter if you like reading this!